നമ്മുക്ക് പരിചയപ്പെടാം
Vaaku2Vec
അത്യാധുനിക ഭാഷാമാതൃക നിർമ്മാണവും വചനവിഭജനവും
എന്താണ് വാക്ക്2വെക്ക്?
വാക്ക്2വെക്ക് എന്നത് ഭാഷാ മാതൃക നിർമ്മാണത്തിനും വചനവിഭജനത്തിനുമായി ഉപയോഗിക്കാവുന്ന ഒരു വാക്ക് എംബെഡ്ഡിങ്ങ് ലൈബ്രറി ആണ്.
വചനവിഭ... എന്ത്?

വാക്ക് എംബെഡ്ഡിങ്ങ് എന്നാൽ കൃത്രിമ ബുദ്ധിശക്തി (ആർട്ടിഫിഷ്യൽ ഇന്റലിജൻസ്) ഉണ്ടാക്കുന്ന രീതികളിൽ ഒന്നാണ്. വാക്കുകൾ ഉപയോഗിച്ചിട്ടുള്ള പശ്ചാത്തലങ്ങൾ പഠിച്ചതിനു ശേഷം ഈ അറിവ് ഗണിതത്തിലെ വെക്റ്റർ (Vector) എന്ന രൂപമാതൃകയിൽ കംപ്യൂട്ടറിന് സുഗമമായി മനസ്സിലാക്കാവുന്ന രൂപത്തിലാക്കുന്നു. വാക്കുകളുടെ പശ്ചാത്തലത്തിനു പുറമെ മറ്റു ചില സ്വഭാവ ഘടകങ്ങളും ഇതിന് സഹായിക്കുവാനായി ഉപയോഗിക്കാറുണ്ട്. ഉദാഹരണത്തിന്:
“റിച്ചു എയർ ഗൺ അൺബോക്സ് ചെയ്തു” എന്ന വാക്യത്തിൽ “എയർ ഗൺ” എന്ന പദം റിച്ചുവിനും അൺബോക്സ് എന്നതിനും ഇടയിൽ വരുന്ന വിവരം കമ്പ്യൂട്ടർ ഈ വചനം വായിച്ചതിനുശേഷം ഭാവിപ്രവർത്തനങ്ങൾക്കായി സൂക്ഷിക്കുന്നു.

അതിത്തിരി കട്ടിയായിപ്പോയി എന്നാലും എന്തൊക്കെയോ പിടികിട്ടീ എന്നു തോന്നുന്നു. ഇതെവിടെയാണ് ഉപയോഗിക്കുന്നത്?
ഇങ്ങനെ ലഭിച്ച വെക്റ്റർ ഡാറ്റ പലരീതിയിലും ഉപയോഗിക്കാവുന്നതാണ്. ആമസോൺ വെബ്സൈറ്റിൽ നമ്മൾ സെർച്ച് ചെയ്യുന്ന വസ്തുക്കളോട് സാമ്യമുള്ള വസ്തുക്കളെ ഹാജരാക്കാൻ ഈ രീതി ഉപകരിക്കും. നമ്മുടെ സ്മാർട്ട്ഫോണുകളിൽ കാണുന്ന സിരി, അലെക്സാ തുടങ്ങി നമ്മുടെ കീബോർഡ് സജഷൻസിൽ അടുത്ത വാക്ക് ഏതാണെന്ന് കണ്ടുപിടിക്കുന്നിടത്തു വരെ ഇത് അപ്ലിക്കേഷൻ കണ്ടെത്തിയിട്ടുണ്ട്.

ഇതെല്ലാം വായിക്കുമ്പോൾ ഗൂഗിൾ സെർച്ച് ചെയ്യുമ്പോൾ ഇതിന്റെ ഉപയോഗം ഉണ്ടോ എന്ന് നിങ്ങളുടെ ചിന്ത പോയെങ്കിൽ നിങ്ങൾ ശരിയായ രീതിയിൽ തന്നെയാണ് ചിന്തിച്ചത്. ഇതിന്റെ ഉത്ഭവം തന്നെ ഗൂഗിളിൽ ആണ്.
ഇത് കൊള്ളാലോ! ആരാ ഇതുണ്ടാക്കിയത്?

ആശ്ചര്യലേശമന്യേ ഗൂഗിൾ ലാബ്സിലെ റിസേർച്ചിൽ നിന്ന് തന്നെയാണ് ഈ പ്രോഡക്റ്റിന്റെ ഉത്ഭവം. തോമസ് മൈകോളവും ടീമും ചേർന്നുള്ള 2013ലെ പൈപ്പറിലാണ് ഈ സാങ്കേതിക രീതി ആദ്യമായി അവതരിപ്പിക്കപ്പെടുന്നത്. ഇതാണ് ആ പേപ്പർ: Distributed Representations of Words and Phrases and their Compositionality (2013)
ഈ ബ്ലോഗ്പോസ്റ്റിൽ പ്രതിപാദിക്കുന്ന Vaaku2vec ആവട്ടെ കമൽ കെ രാജ്, ആദം ഷംസുദ്ദീൻ എന്നിവർ ചേർന്ന് വികസിപ്പിച്ചെടുത്തതാണ്. കമലും ആദം ഷംസുദ്ദീനും IndicNLP യുടെ അംഗങ്ങളാണ്. 2019 ആദ്യമാണ് ഇതിന്റെ ഉത്ഭവം.

അല്ല അപ്പൊ ഈ Word2Vec ഉള്ളപോലെന്തിനാ Vaaku2Vec?
ഇതിന്റെ Github repoവിൽ പറയുന്നത് പോലെ മലയാളം ഇൻഫ്ലക്ഷൻസും അഗ്ഗ്ലൂറ്റിനേഷനുകളും ഉള്ള ഭാഷയാണ്. അതായത്:
ഇത് (this) + ആണ് (is) എന്നുള്ളത് മലയാളത്തിൽ ഇതാണ് (this is) എന്നാക്കി മാറ്റാമല്ലോ.
ഇതിനൊത്ത് പ്രവർത്തിക്കാനായി ഈ അൽഗോറിതങ്ങളെ ചിട്ടപ്പെടുത്തേണ്ടത് ആവശ്യമാണ്. ഈ ജോലിയാണ് കമലും ഷംസുദ്ദീനും നിർവഹിച്ചിട്ടുള്ളത്. ഇതിലുപരി ഈ അൽഗോറിതങ്ങളെ പല മലയാള വിവരശേഖരങ്ങളിലും പയറ്റി തെളിയിക്കുകയും (text classification) ഇവർ ചെയ്തിട്ടുണ്ട്.
അടിപൊളി, അപ്പൊ ഇതെവിടുന്ന് കിട്ടും?
പിന്നെ ഇതിന്റെ ഒരു demo ഈ വെബ്സൈറ്റിൽ ഉണ്ട്.
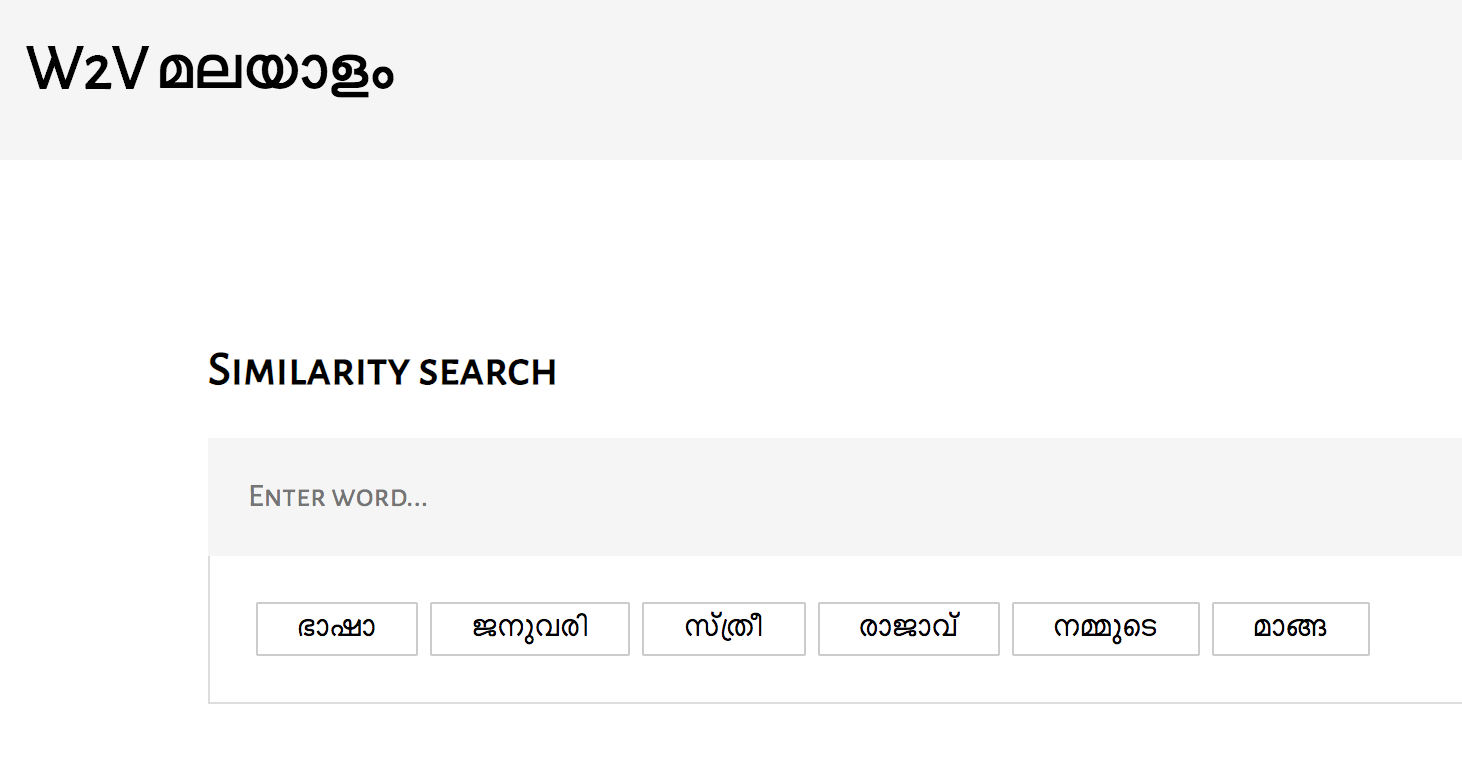
ഇത് ഞാൻ ഡൗൺലോഡ് ചെയ്തു. ഇനി എന്ത് ചെയ്യണം?
ആദ്യ പടി ഇതിനെ പറ്റി നല്ല ഗ്രാഹ്യമുണ്ടാക്കുകയാണ്. അതിനായി ഞങ്ങൾ ഈ ബ്ലോഗ്പോസ്റ്റ് എഴുതാൻ പര്യന്വേഷണം നടത്തിയപ്പോൾ കിട്ടിയ ഒരു ലിങ്ക് പങ്കു വെയ്ക്കുകയാണ്:
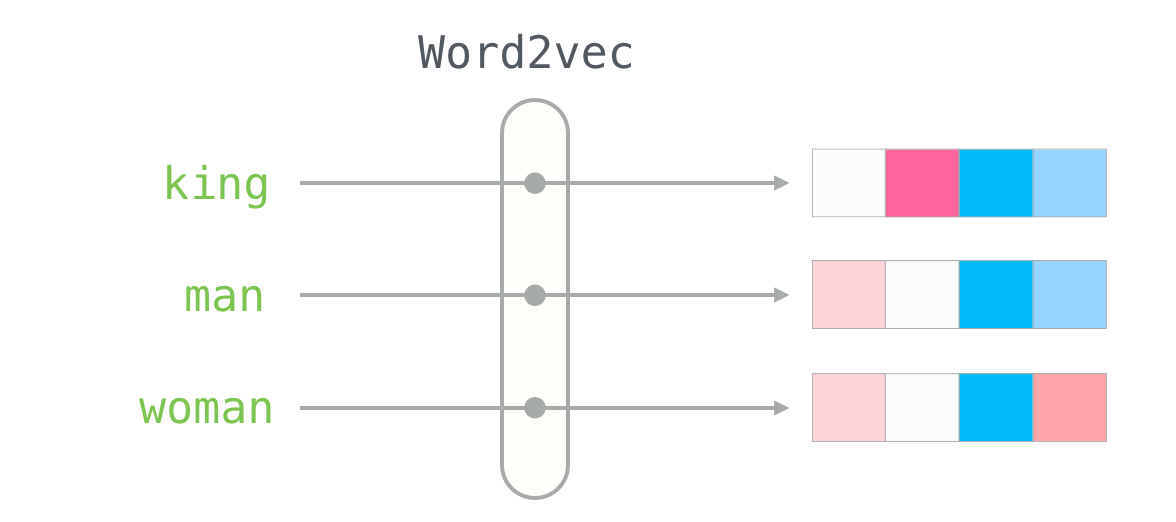
ഇത് മനസിലാക്കി കഴിഞ്ഞാൽ നിങ്ങൾക്ക് പുതിയ ആശയങ്ങൾ മനസ്സിൽ തെളിയുകയാണെങ്കിൽ അവ പിന്തുടരുകയോ ഇല്ലെങ്കിൽ ഈ പ്രോജെക്റ്റിന്റെ TODO സെക്ഷനിൽ എഴുതിയിട്ടുള്ള ഏതെങ്കിലും കർത്തവ്യം പൂർത്തിയാക്കുകയോ ചെയ്യാം.
ഇത്തരത്തിലുള്ള വാർത്തകൾ ഉടനടി അറിയാൻ മേക്കർ ബ്രോഡ്കാസ്റ്റ് സബ്സ്ക്ക്രൈബ് ചെയ്യുക